2018 Workshop at the Academy of Management Annual Meeting
First time setup in R
In order to follow the code developed for the workshop (shown in full below under Workshop example), two pieces of software need to be installed beforehand. The first is R, a free software environment for statistical computing and graphics. The second is RStudio, which is a graphical user interface that goes ‘over’ R, making it more user friendly. It is adamant that R is installed first, and RStudio second.
Before running the code shown below, install R on your system by going to the following page: https://cran.r-project.org/ Here, OS-specific versions of R can be found. For example, by clicking here, you can download the executable for Windows. For Mac OS X, the install file can be found here. Installation using the default settings should do the trick.
Then, after the installation of R is complete, navigate to the following page: https://www.rstudio.com/ You can download the free version of RStudio on this page. Again, the default settings should do the trick.
Then, after these steps are completed, it is advisable to run the following two lines of code in RStudio before coming to the workshop.
# The "tm" package enables the text mining infrastructure that we will use for LDA.
if (!require("tm")) install.packages("tm")
# The "topicmodels" package enables LDA analysis.
if (!require("topicmodels")) install.packages("topicmodels")
# The "LDAVis" package enables visualization from the LDA analysis.
if (!require("LDAVis")) install.packages("LDAVis")
# The "servr" is used by LDAVis.
if (!require("servr")) install.packages("servr")
# The "igraph" package enables creation of networks.
if (!require("igraph")) install.packages("igraph")
These will install the core packages that we will use in the workshop, and their installation may take some time on the standard conference internet connection. After this is done, you’re all set to participate in the workshop! It is also possible to run the code shown below at home beforehand, but note that the actual topic model takes a LONG time to finish on most PCs.
You can install packages by entering them to your script (you can start a new script on Windows via “Shift+Ctrl+N” or by navigating to “File” –> “New File” –> “R Script”. You can run code by selecting the code and pressing “Ctrl + Enter” or the “Run” button at the top of the script window. Packages can also be installed by navigating to “Packages” (which should be on the right half of your screen), or by selecting “Tools” at the top of your screen and selecting “Install packages” from there.
2018 Workshop example
Texts on electric vehicles: 2005-2014. ——————- Code tested and written for R version 3.5.1, tm package version 0.7-4, topicmodels package version 0.2-7, igraph version 1.2.1., and LDAVis version 0.3.2.
Code prepared on July 30, 2018 by Richard Haans (haans@rsm.nl). Data obtained from Hovig Tchalian, used with permission.
Loading packages
# The following command loads the required packages.
library(topicmodels)
library(tm)
library(LDAvis)
library(igraph)
Get the data, turn into a corpus, and clean it up
For more information with regards to cleaning, please see the PDW from last year. It can be found here
#########################################
### Data loading
#########################################
corpus_pr <-Corpus(DirSource("Texts\\PR"), readerControl = list(reader=readPlain))
corpus_general <-Corpus(DirSource("Texts\\General"), readerControl = list(reader=readPlain))
# Note that R loads up the texts in alphabetic order based on the filename, even though the folder itself
# was not sorted in this way. It is always good to check how the data are organized after loading to prevent
# errors in data combination further down the road.
# These files were read locally, but for ease of use, use the command below to load the starting file:
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2018/Data_pr.RData?raw=true"))
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2018/Data_general.RData?raw=true"))
#########################################
### Cleaning up the corpus
#########################################
# Below, we clean up the documents in various steps.
# We write everything to a new corpus called "corpusclean" so that we do not lose the original data.
# 1) Remove numbers
corpusclean_pr <- tm_map(corpus_pr, removeNumbers)
# 2) Remove punctuation
corpusclean_pr <- tm_map(corpusclean_pr, removePunctuation)
# 3) Transform all upper-case letters to lower-case.
corpusclean_pr <- tm_map(corpusclean_pr, content_transformer(tolower))
# 4) Remove stopwords which do not convey any meaning.
corpusclean_pr <- tm_map(corpusclean_pr, removeWords, stopwords("english")) # this stopword file is at C:\Users\[username]\Documents\R\win-library\2.13\tm\stopwords
# 5) And strip whitespace.
corpusclean_pr <- tm_map(corpusclean_pr , stripWhitespace)
# 1) Remove numbers
corpusclean_general <- tm_map(corpus_general, removeNumbers)
# 2) Remove punctuation
corpusclean_general <- tm_map(corpusclean_general, removePunctuation)
# 3) Transform all upper-case letters to lower-case.
corpusclean_general <- tm_map(corpusclean_general, content_transformer(tolower))
# 4) Remove stopwords which do not convey any meaning.
corpusclean_general <- tm_map(corpusclean_general, removeWords, stopwords("english")) # this stopword file is at C:\Users\[username]\Documents\R\win-library\2.13\tm\stopwords
# 5) And strip whitespace.
corpusclean_general <- tm_map(corpusclean_general , stripWhitespace)
# See the help of getTransformations for more possibilities, such as stemming.
#########################################
### More cleaning: infrequent words and frequent words
#########################################
# We convert the corpus to a "Document-term-matrix" (dtm)
dtm_pr <-DocumentTermMatrix(corpusclean_pr)
dtm_general <-DocumentTermMatrix(corpusclean_general)
# dtms are organized with rows being documents and columns being the unique words.
# To speed up the computation process for this tutorial, I have selected some of the most frequent words
# that don't seem to be very meaningful.
# We update the corpusclean corpus by removing these words.
corpusclean_pr <- tm_map(corpusclean_pr, removeWords, c("words","also","can","get","going","just","well","said","will","thats","now","right","like","last","one","see"))
corpusclean_general <- tm_map(corpusclean_general, removeWords, c("words","also","can","get","going","just","well","said","will","thats","now","right","like","last","one","see"))
# We then create a dictionary that contains words occurring more than 50 times.
highfreq50_pr <- findFreqTerms(dtm_pr,50,Inf)
highfreq50_general <- findFreqTerms(dtm_general,50,Inf)
# and create a smaller dtm
# Note that this is completed on the corpus, not the DTM.
smalldtm_50w_pr <- DocumentTermMatrix(corpusclean_pr, control=list(dictionary = highfreq50_pr))
smalldtm_50w_general <- DocumentTermMatrix(corpusclean_general, control=list(dictionary = highfreq50_general))
# The following loads the data after processing via the above steps:
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2018/Data_preTM.RData?raw=true"))
LDA: Running the model
Please see the PDW from last year for some more information on the basic models. It can be found here
# We first fix the random seed for future replication.
SEED <- 123456789
#########################################
# 10 Topics
t1_10_pr <- Sys.time()
LDA10_pr <- LDA(smalldtm_50w_pr, k = 10, control = list(seed = SEED, verbose = 1))
t2_10_pr <- Sys.time()
t1_10_general <- Sys.time()
LDA10_general <- LDA(smalldtm_50w_general, k = 10, control = list(seed = SEED, verbose = 1))
t2_10_general <- Sys.time()
# Assess time it took to run:
t2_10_pr- t1_10_pr
t2_10_general- t1_10_general
#########################################
# 25 Topics
t1_25_pr <- Sys.time()
LDA25_pr <- LDA(smalldtm_50w_pr, k = 25, control = list(seed = SEED, verbose = 1))
t2_25_pr <- Sys.time()
t1_25_general <- Sys.time()
LDA25_general <- LDA(smalldtm_50w_general, k = 25, control = list(seed = SEED, verbose = 1))
t2_25_general <- Sys.time()
# Assess time it took to run:
t2_25_pr- t1_25_pr
t2_25_general- t1_25_general
#########################################
# 50 Topics
t1_50_pr <- Sys.time()
LDA50_pr <- LDA(smalldtm_50w_pr, k = 50, control = list(seed = SEED, verbose = 1))
t2_50_pr <- Sys.time()
t1_50_general <- Sys.time()
LDA50_general <- LDA(smalldtm_50w_general, k = 50, control = list(seed = SEED, verbose = 1))
t2_50_general <- Sys.time()
# Assess time it took to run:
t2_50_pr- t1_50_pr
t2_50_general- t1_50_general
LDA: Rendering
#########################################
# Terms per topic
#########################################
# 10 topics
# We then create a variable that captures the top ten terms assigned to the 10-topic model:
topics_LDA10_pr <- terms(LDA10_pr, 10)
# And show the results:
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Topic 6
[1,] "million" "market" "technology" "market" "market" "new"
[2,] "new" "think" "vehicles" "million" "year" "electric"
[3,] "company" "growth" "energy" "sales" "company" "business"
[4,] "information" "million" "power" "energy" "think" "company"
[5,] "markets" "new" "year" "year" "sales" "vehicle"
[6,] "electric" "company" "business" "industry" "business" "million"
[7,] "statements" "energy" "new" "quarter" "electric" "year"
[8,] "quarter" "products" "market" "automotive" "first" "power"
[9,] "power" "year" "systems" "growth" "table" "vehicles"
[10,] "energy" "customers" "statements" "time" "power" "inc"
Topic 7 Topic 8 Topic 9 Topic 10
[1,] "business" "new" "electric" "company"
[2,] "year" "growth" "market" "year"
[3,] "new" "energy" "energy" "quarter"
[4,] "think" "inc" "quarter" "vehicle"
[5,] "energy" "electric" "think" "product"
[6,] "sales" "business" "million" "think"
[7,] "first" "million" "global" "million"
[8,] "time" "customers" "battery" "business"
[9,] "companies" "tesla" "question" "new"
[10,] "today" "financial" "year" "operating"
topics_LDA10_general <- terms(LDA10_general, 10)
# And show the results:
topics_LDA10_general
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Topic 6
[1,] "car" "electric" "know" "new" "people" "tesla"
[2,] "vehicles" "time" "cars" "first" "energy" "new"
[3,] "electric" "year" "president" "obama" "say" "company"
[4,] "cars" "president" "people" "company" "make" "percent"
[5,] "new" "price" "year" "think" "think" "year"
[6,] "company" "cars" "john" "electric" "new" "million"
[7,] "year" "company" "dont" "car" "auto" "pct"
[8,] "gas" "global" "big" "vehicles" "billion" "inc"
[9,] "energy" "million" "time" "million" "know" "electric"
[10,] "first" "high" "years" "hes" "years" "sent"
Topic 7 Topic 8 Topic 9 Topic 10
[1,] "contact" "price" "price" "price"
[2,] "new" "total" "electric" "average"
[3,] "holds" "new" "total" "month"
[4,] "location" "year" "stock" "day"
[5,] "national" "day" "market" "usd"
[6,] "house" "energy" "high" "stock"
[7,] "street" "assets" "day" "company"
[8,] "energy" "times" "year" "market"
[9,] "conference" "month" "month" "year"
[10,] "president" "market" "insider" "energy"
#########################################
# 25 topics
topics_LDA25_pr <- terms(LDA25_pr, 25)
# And show the results:
topics_LDA25_pr
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "million" "market" "business" "energy" "market"
[2,] "quarter" "energy" "new" "market" "business"
[3,] "statements" "company" "year" "sales" "year"
[4,] "years" "think" "think" "million" "sales"
[5,] "think" "years" "electric" "markets" "think"
[6,] "company" "year" "market" "year" "company"
[7,] "new" "new" "energy" "automotive" "table"
[8,] "fuel" "weve" "million" "industry" "electric"
[9,] "two" "growth" "vehicles" "growth" "first"
[10,] "technology" "vehicles" "statements" "years" "energy"
Topic 6 Topic 7 Topic 8 Topic 9 Topic 10
[1,] "company" "year" "business" "market" "year"
[2,] "year" "business" "energy" "electric" "quarter"
[3,] "new" "think" "electric" "energy" "think"
[4,] "power" "new" "new" "quarter" "company"
[5,] "two" "markets" "growth" "information" "business"
[6,] "million" "energy" "market" "think" "million"
[7,] "electric" "first" "customers" "question" "years"
[8,] "think" "two" "results" "year" "new"
[9,] "industrial" "technology" "dont" "technology" "vehicle"
[10,] "vehicles" "vehicles" "global" "global" "first"
Topic 11 Topic 12 Topic 13 Topic 14 Topic 15
[1,] "new" "year" "market" "quarter" "million"
[2,] "million" "hybrid" "new" "business" "year"
[3,] "quarter" "technology" "business" "electric" "sales"
[4,] "business" "vehicles" "million" "new" "time"
[5,] "vehicle" "power" "power" "think" "vehicles"
[6,] "market" "electric" "company" "time" "product"
[7,] "statements" "systems" "electric" "year" "vehicle"
[8,] "company" "company" "sales" "growth" "business"
[9,] "fuel" "quarter" "growth" "energy" "quarter"
[10,] "technology" "first" "vehicles" "million" "power"
Topic 16 Topic 17 Topic 18 Topic 19 Topic 20
[1,] "vehicle" "market" "million" "company" "new"
[2,] "market" "electric" "electric" "energy" "year"
[3,] "million" "quarter" "year" "technology" "energy"
[4,] "new" "growth" "quarter" "sales" "technology"
[5,] "company" "new" "market" "electric" "power"
[6,] "think" "sales" "first" "car" "global"
[7,] "energy" "customers" "sales" "vehicles" "vehicles"
[8,] "product" "vehicle" "industry" "million" "think"
[9,] "technology" "industry" "energy" "markets" "information"
[10,] "growth" "think" "companies" "think" "sales"
Topic 21 Topic 22 Topic 23 Topic 24 Topic 25
[1,] "market" "market" "electric" "new" "market"
[2,] "year" "business" "market" "year" "think"
[3,] "energy" "million" "company" "million" "company"
[4,] "business" "technology" "million" "growth" "million"
[5,] "million" "electric" "business" "company" "sales"
[6,] "technology" "think" "new" "market" "technology"
[7,] "vehicle" "products" "think" "years" "years"
[8,] "car" "battery" "energy" "inc" "products"
[9,] "electric" "vehicles" "vehicles" "markets" "year"
[10,] "products" "share" "year" "information" "statements"
topics_LDA25_general <- terms(LDA25_general, 25)
# And show the results:
topics_LDA25_general
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Topic 6
[1,] "company" "year" "know" "obama" "people" "tesla"
[2,] "pct" "car" "people" "car" "cars" "electric"
[3,] "year" "years" "year" "year" "years" "year"
[4,] "vehicles" "ago" "time" "think" "car" "new"
[5,] "car" "price" "years" "hes" "billion" "company"
[6,] "cars" "people" "big" "today" "think" "cars"
[7,] "electric" "month" "cars" "mccain" "market" "sent"
[8,] "energy" "cars" "street" "first" "year" "state"
[9,] "million" "global" "john" "electric" "time" "inc"
[10,] "tesla" "electric" "says" "companies" "states" "pct"
Topic 7 Topic 8 Topic 9 Topic 10 Topic 11 Topic 12
[1,] "contact" "total" "deadline" "energy" "electric" "year"
[2,] "location" "new" "dec" "price" "year" "total"
[3,] "holds" "price" "new" "day" "assets" "electric"
[4,] "new" "day" "car" "company" "new" "price"
[5,] "national" "year" "cars" "month" "energy" "index"
[6,] "president" "month" "vehicles" "new" "know" "million"
[7,] "house" "energy" "nov" "shares" "state" "market"
[8,] "conference" "company" "gas" "stock" "really" "week"
[9,] "director" "assets" "notified" "assets" "day" "time"
[10,] "street" "market" "hybrid" "capital" "million" "times"
Topic 13 Topic 14 Topic 15 Topic 16 Topic 17 Topic 18
[1,] "new" "new" "new" "new" "price" "new"
[2,] "energy" "car" "day" "car" "stock" "million"
[3,] "electric" "sent" "market" "percent" "company" "electric"
[4,] "company" "moved" "price" "tesla" "new" "percent"
[5,] "contact" "vehicles" "president" "inc" "total" "cars"
[6,] "government" "says" "times" "people" "shares" "first"
[7,] "vehicles" "years" "total" "company" "average" "energy"
[8,] "assets" "photos" "electric" "electric" "times" "general"
[9,] "month" "first" "average" "make" "day" "time"
[10,] "national" "percent" "company" "model" "volume" "company"
Topic 19 Topic 20 Topic 21 Topic 22 Topic 23 Topic 24
[1,] "new" "obama" "electric" "month" "years" "day"
[2,] "energy" "dont" "new" "price" "people" "price"
[3,] "people" "auto" "vehicles" "market" "say" "year"
[4,] "oil" "know" "company" "stock" "new" "total"
[5,] "house" "new" "president" "year" "think" "market"
[6,] "john" "president" "total" "assets" "oil" "electric"
[7,] "cars" "energy" "year" "months" "know" "stocks"
[8,] "think" "first" "price" "energy" "mccain" "index"
[9,] "way" "make" "power" "week" "states" "average"
[10,] "time" "car" "today" "average" "back" "ratio"
Topic 25
[1,] "today"
[2,] "price"
[3,] "company"
[4,] "president"
[5,] "cars"
[6,] "know"
[7,] "car"
[8,] "stocks"
[9,] "percent"
[10,] "director"
#########################################
# 50 topics
topics_LDA50_pr <- terms(LDA50_pr, 50)
# And show the results:
topics_LDA50_pr
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "million" "energy" "market" "market" "market"
[2,] "company" "new" "year" "energy" "year"
[3,] "new" "think" "new" "sales" "business"
[4,] "electric" "market" "business" "year" "sales"
[5,] "power" "power" "million" "million" "company"
Topic 6 Topic 7 Topic 8 Topic 9 Topic 10
[1,] "new" "think" "new" "market" "year"
[2,] "year" "year" "business" "electric" "think"
[3,] "company" "business" "energy" "energy" "quarter"
[4,] "power" "energy" "electric" "think" "business"
[5,] "think" "new" "growth" "quarter" "company"
Topic 11 Topic 12 Topic 13 Topic 14
[1,] "market" "power" "market" "electric"
[2,] "quarter" "vehicles" "new" "new"
[3,] "sales" "year" "business" "energy"
[4,] "new" "company" "million" "think"
[5,] "company" "technology" "sales" "million"
Topic 15 Topic 16 Topic 17 Topic 18 Topic 19
[1,] "million" "new" "market" "million" "electric"
[2,] "year" "market" "electric" "year" "energy"
[3,] "sales" "energy" "growth" "electric" "company"
[4,] "power" "think" "sales" "energy" "million"
[5,] "vehicle" "company" "quarter" "quarter" "global"
Topic 20 Topic 21 Topic 22 Topic 23 Topic 24
[1,] "new" "market" "business" "electric" "new"
[2,] "year" "million" "think" "market" "year"
[3,] "energy" "business" "market" "company" "million"
[4,] "sales" "year" "million" "business" "years"
[5,] "vehicles" "energy" "vehicles" "think" "company"
Topic 25 Topic 26 Topic 27 Topic 28
[1,] "market" "new" "million" "million"
[2,] "company" "electric" "electric" "technology"
[3,] "sales" "year" "think" "business"
[4,] "technology" "business" "year" "new"
[5,] "think" "power" "markets" "company"
Topic 29 Topic 30 Topic 31 Topic 32 Topic 33
[1,] "million" "think" "energy" "vehicle" "think"
[2,] "quarter" "electric" "million" "electric" "quarter"
[3,] "market" "business" "electric" "quarter" "new"
[4,] "year" "energy" "business" "year" "million"
[5,] "power" "vehicle" "quarter" "new" "vehicles"
Topic 34 Topic 35 Topic 36 Topic 37
[1,] "electric" "company" "energy" "year"
[2,] "year" "quarter" "million" "new"
[3,] "first" "market" "think" "million"
[4,] "market" "statements" "vehicles" "energy"
[5,] "information" "year" "business" "business"
Topic 38 Topic 39 Topic 40 Topic 41
[1,] "market" "business" "time" "vehicles"
[2,] "new" "electric" "sales" "quarter"
[3,] "year" "year" "first" "power"
[4,] "company" "market" "year" "energy"
[5,] "sales" "million" "vehicles" "million"
Topic 42 Topic 43 Topic 44 Topic 45 Topic 46
[1,] "business" "market" "market" "market" "business"
[2,] "markets" "million" "company" "company" "market"
[3,] "company" "energy" "energy" "year" "sales"
[4,] "growth" "power" "year" "think" "electric"
[5,] "million" "quarter" "vehicles" "energy" "energy"
Topic 47 Topic 48 Topic 49 Topic 50
[1,] "market" "electric" "market" "business"
[2,] "business" "energy" "year" "quarter"
[3,] "first" "million" "years" "company"
[4,] "quarter" "market" "company" "new"
[5,] "company" "think" "think" "year"
topics_LDA50_general <- terms(LDA50_general, 50)
# And show the results:
topics_LDA50_general
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "cars" "year" "year" "obama" "people"
[2,] "year" "car" "obama" "think" "president"
[3,] "vehicles" "cars" "know" "today" "think"
[4,] "company" "electric" "cars" "electric" "energy"
[5,] "electric" "month" "people" "car" "know"
Topic 6 Topic 7 Topic 8 Topic 9 Topic 10
[1,] "tesla" "president" "new" "deadline" "new"
[2,] "company" "contact" "total" "new" "price"
[3,] "electric" "location" "price" "car" "energy"
[4,] "state" "holds" "day" "cars" "company"
[5,] "cars" "electric" "year" "notified" "day"
Topic 11 Topic 12 Topic 13 Topic 14 Topic 15
[1,] "electric" "electric" "electric" "company" "new"
[2,] "year" "total" "new" "assets" "day"
[3,] "new" "year" "company" "new" "sales"
[4,] "energy" "price" "energy" "billion" "market"
[5,] "know" "times" "vehicles" "vehicles" "electric"
Topic 16 Topic 17 Topic 18 Topic 19 Topic 20
[1,] "new" "times" "new" "new" "obama"
[2,] "pct" "price" "electric" "oil" "new"
[3,] "inc" "average" "cars" "energy" "know"
[4,] "company" "shares" "million" "think" "auto"
[5,] "percent" "stock" "company" "people" "make"
Topic 21 Topic 22 Topic 23 Topic 24 Topic 25 Topic 26
[1,] "electric" "month" "think" "price" "cars" "vehicles"
[2,] "new" "market" "say" "day" "today" "cars"
[3,] "president" "price" "new" "electric" "president" "say"
[4,] "price" "week" "people" "market" "company" "energy"
[5,] "year" "stock" "know" "average" "price" "first"
Topic 27 Topic 28 Topic 29 Topic 30 Topic 31
[1,] "price" "mccain" "year" "market" "price"
[2,] "day" "know" "electric" "new" "electric"
[3,] "year" "two" "new" "stock" "obama"
[4,] "month" "years" "cars" "energy" "president"
[5,] "stock" "year" "house" "month" "first"
Topic 32 Topic 33 Topic 34 Topic 35 Topic 36
[1,] "electric" "vehicles" "street" "year" "new"
[2,] "year" "company" "contact" "new" "car"
[3,] "market" "energy" "new" "president" "sent"
[4,] "assets" "people" "people" "company" "million"
[5,] "shares" "united" "president" "million" "tesla"
Topic 37 Topic 38 Topic 39 Topic 40 Topic 41
[1,] "year" "price" "house" "day" "new"
[2,] "total" "total" "contact" "ratio" "location"
[3,] "price" "company" "car" "usd" "american"
[4,] "usd" "stock" "year" "week" "contact"
[5,] "company" "year" "cars" "market" "first"
Topic 42 Topic 43 Topic 44 Topic 45 Topic 46
[1,] "years" "new" "contact" "year" "million"
[2,] "president" "sent" "car" "price" "percent"
[3,] "state" "year" "electric" "president" "electric"
[4,] "new" "vehicles" "pct" "global" "car"
[5,] "tesla" "first" "cars" "day" "company"
Topic 47 Topic 48 Topic 49 Topic 50
[1,] "year" "year" "new" "year"
[2,] "times" "new" "year" "electric"
[3,] "new" "car" "energy" "energy"
[4,] "day" "federal" "company" "total"
[5,] "years" "time" "state" "know"
Getting more precise (document-topic / term-topic) matrices to be used in rendering
# Document-topic matrices
documents_LDA10_pr <- as.data.frame(LDA10_pr@gamma)
documents_LDA10_general <- as.data.frame(LDA10_general@gamma)
documents_LDA25_pr <- as.data.frame(LDA25_pr@gamma)
documents_LDA25_general <- as.data.frame(LDA25_general@gamma)
documents_LDA50_pr <- as.data.frame(LDA50_pr@gamma)
documents_LDA50_general <- as.data.frame(LDA50_general@gamma)
#########################################
# Term-topic matrices
terms_LDA10_pr <- posterior(LDA10_pr)[["terms"]]
terms_LDA10_general <- posterior(LDA10_general)[["terms"]]
terms_LDA25_pr <- posterior(LDA25_pr)[["terms"]]
terms_LDA25_general <- posterior(LDA25_general)[["terms"]]
terms_LDA50_pr <- posterior(LDA50_pr)[["terms"]]
terms_LDA50_general <- posterior(LDA50_general)[["terms"]]
#########################################
# Write tables
write.table(documents_LDA10_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_10_pr.csv", sep=',',row.names = FALSE)
write.table(documents_LDA10_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_10_general.csv", sep=',',row.names = FALSE)
write.table(documents_LDA25_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_25_pr.csv", sep=',',row.names = FALSE)
write.table(documents_LDA25_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_25_general.csv", sep=',',row.names = FALSE)
write.table(documents_LDA50_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_50_pr.csv", sep=',',row.names = FALSE)
write.table(documents_LDA50_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\documents_50_general.csv", sep=',',row.names = FALSE)
write.table(terms_LDA10_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_10_pr.csv", sep=',',row.names = FALSE)
write.table(terms_LDA10_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_10_general.csv", sep=',',row.names = FALSE)
write.table(terms_LDA25_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_25_pr.csv", sep=',',row.names = FALSE)
write.table(terms_LDA25_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_25_general.csv", sep=',',row.names = FALSE)
write.table(terms_LDA50_pr, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_50_pr.csv", sep=',',row.names = FALSE)
write.table(terms_LDA50_general, file = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\terms_50_general.csv", sep=',',row.names = FALSE)
Creating topic networks (based on term correlations)
# Get the term-topic matrices again
post_10_pr <- topicmodels::posterior(LDA10_pr)
post_10_general <- topicmodels::posterior(LDA10_general)
post_25_pr <- topicmodels::posterior(LDA25_pr)
post_25_general <- topicmodels::posterior(LDA25_general)
post_50_pr <- topicmodels::posterior(LDA50_pr)
post_50_general <- topicmodels::posterior(LDA50_general)
# Create correlation matrices between the topics based on their term-loadings
cor_mat_10_pr <- cor(t(post_10_pr[["terms"]]))
cor_mat_10_general <- cor(t(post_10_general[["terms"]]))
cor_mat_25_pr <- cor(t(post_25_pr[["terms"]]))
cor_mat_25_general <- cor(t(post_25_general[["terms"]]))
cor_mat_50_pr <- cor(t(post_50_pr[["terms"]]))
cor_mat_50_general <- cor(t(post_50_general[["terms"]]))
# Change row values to zero if less than row minimum plus two times the row standard deviation
# The two times was chosen for illustrative purposes.
# This is similar to how Jockers subsets the distance matrix to keep only
# closely related documents and avoid a dense spagetti diagram
# that's difficult to interpret (hat-tip: http://stackoverflow.com/a/16047196/1036500)
cor_mat_10_pr[ sweep(cor_mat_10_pr, 1, (apply(cor_mat_10_pr,1,min) + 2*apply(cor_mat_10_pr,1,sd) )) < 0 ] <- 0
diag(cor_mat_10_pr) <- 0
cor_mat_10_general[ sweep(cor_mat_10_general, 1, (apply(cor_mat_10_general,1,min) + 2*apply(cor_mat_10_general,1,sd) )) < 0 ] <- 0
diag(cor_mat_10_general) <- 0
cor_mat_25_pr[ sweep(cor_mat_25_pr, 1, (apply(cor_mat_25_pr,1,min) + 2*apply(cor_mat_25_pr,1,sd) )) < 0 ] <- 0
diag(cor_mat_25_pr) <- 0
cor_mat_25_general[ sweep(cor_mat_25_general, 1, (apply(cor_mat_25_general,1,min) + 2*apply(cor_mat_25_general,1,sd) )) < 0 ] <- 0
diag(cor_mat_25_general) <- 0
cor_mat_50_pr[ sweep(cor_mat_50_pr, 1, (apply(cor_mat_50_pr,1,min) + 2*apply(cor_mat_50_pr,1,sd) )) < 0 ] <- 0
diag(cor_mat_50_pr) <- 0
cor_mat_50_general[ sweep(cor_mat_50_general, 1, (apply(cor_mat_50_general,1,min) + 2*apply(cor_mat_50_general,1,sd) )) < 0 ] <- 0
diag(cor_mat_50_general) <- 0
# And create graphs:
g_10_pr <- igraph::graph.adjacency(cor_mat_10_pr, weighted = TRUE , mode= 'undirected')
plot(g_10_pr, layout = layout_with_kk,
edge.width=E(g_10_pr)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")
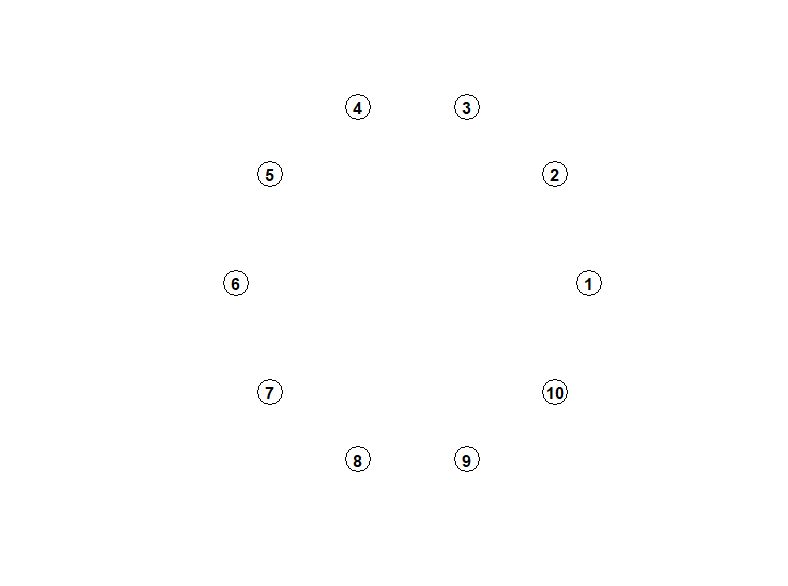
g_10_general <- igraph::graph.adjacency(cor_mat_10_general, weighted = TRUE , mode= 'undirected')
plot(g_10_general, layout = layout_with_kk,
edge.width=E(g_10_general)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")
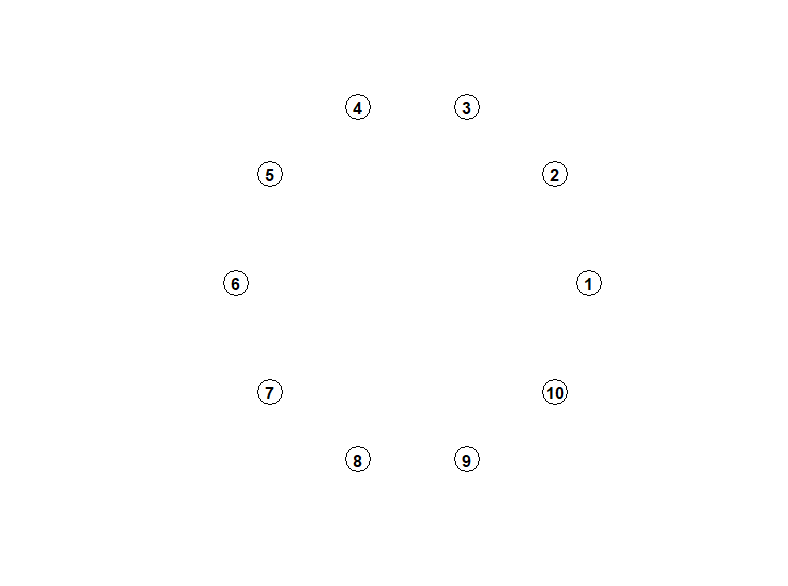
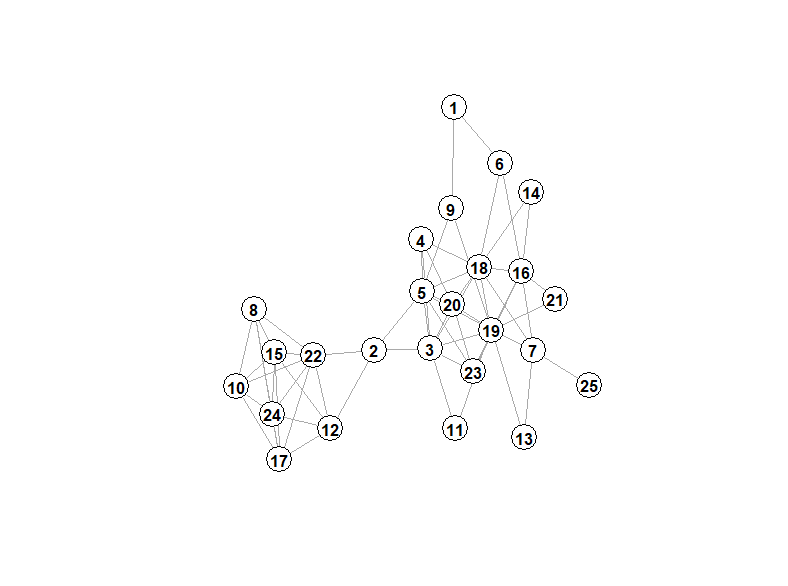
g_25_pr <- igraph::graph.adjacency(cor_mat_25_pr, weighted = TRUE , mode= 'undirected')
plot(g_25_pr, layout = layout_with_kk,
edge.width=E(g_25_pr)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")

g_25_general <- igraph::graph.adjacency(cor_mat_25_general, weighted = TRUE , mode= 'undirected')
plot(g_25_general, layout = layout_with_kk,
edge.width=E(g_25_general)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")
g_50_pr <- igraph::graph.adjacency(cor_mat_50_pr, weighted = TRUE , mode= 'undirected')
plot(g_50_pr, layout = layout_with_kk,
edge.width=E(g_50_pr)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")

g_50_general <- igraph::graph.adjacency(cor_mat_50_general, weighted = TRUE , mode= 'undirected')
plot(g_50_general, layout = layout_with_kk,
edge.width=E(g_50_general)$weight,
vertex.label.family = "sans",vertex.label.font=2, vertex.color = "white", vertex.label.color = "black")

Using LDAVis to visualize topics
# We need to create a function that allows converting LDA output from the 'topicmodels' package to LDAVis
# https://gist.github.com/trinker/477d7ae65ff6ca73cace
#' Transform Model Output for Use with the LDAvis Package
topicmodels2LDAvis <- function(x, ...){
post <- topicmodels::posterior(x)
if (ncol(post[["topics"]]) < 3) stop("The model must contain > 2 topics")
mat <- x@wordassignments
LDAvis::createJSON(
phi = post[["terms"]],
theta = post[["topics"]],
vocab = colnames(post[["terms"]]),
doc.length = slam::row_sums(mat, na.rm = TRUE),
term.frequency = slam::col_sums(mat, na.rm = TRUE)
)
}
LDAvis::serVis(topicmodels2LDAvis(LDA10_pr), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_10_pr", open.browser = FALSE)
LDAvis::serVis(topicmodels2LDAvis(LDA10_general), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_10_general", open.browser = FALSE)
LDAvis::serVis(topicmodels2LDAvis(LDA25_pr), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_25_pr", open.browser = FALSE)
LDAvis::serVis(topicmodels2LDAvis(LDA25_general), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_25_general", open.browser = FALSE)
LDAvis::serVis(topicmodels2LDAvis(LDA50_pr), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_50_pr", open.browser = FALSE)
LDAvis::serVis(topicmodels2LDAvis(LDA50_general), out.dir = "C:\\Users\\rfjha\\Documents\\GitHub\\topicmodeling\\Output\\2018\\LDAVis\\vis_50_general", open.browser = FALSE)
# The following URL points to the data with all the output
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2018/Data_LDA.RData?raw=true"))
Please see this paper for more information on this visualization (Sievert and Shirley, 2014).
You can access interactive versions of the images below by clicking the figure title (e.g. “10-topic PR”).
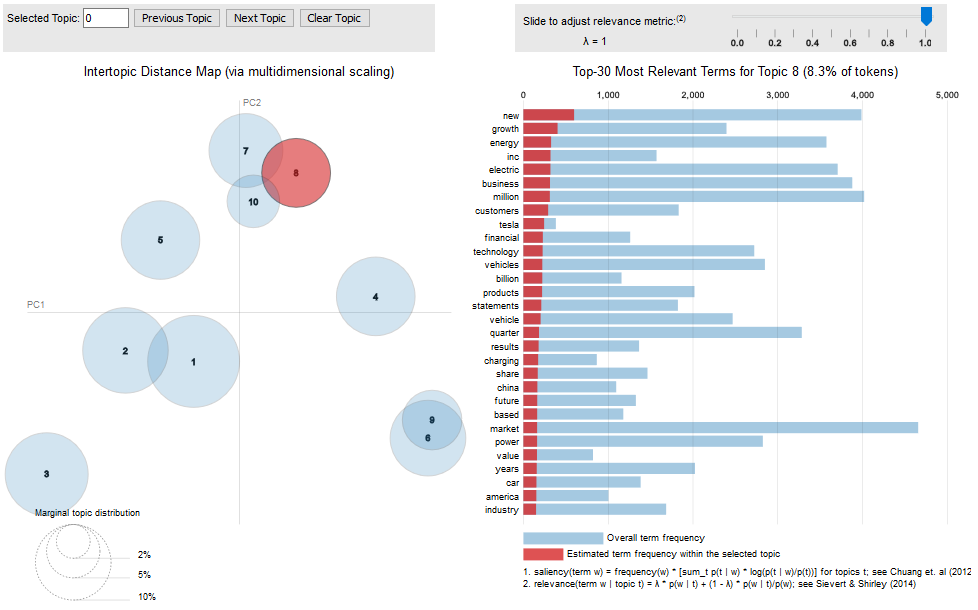
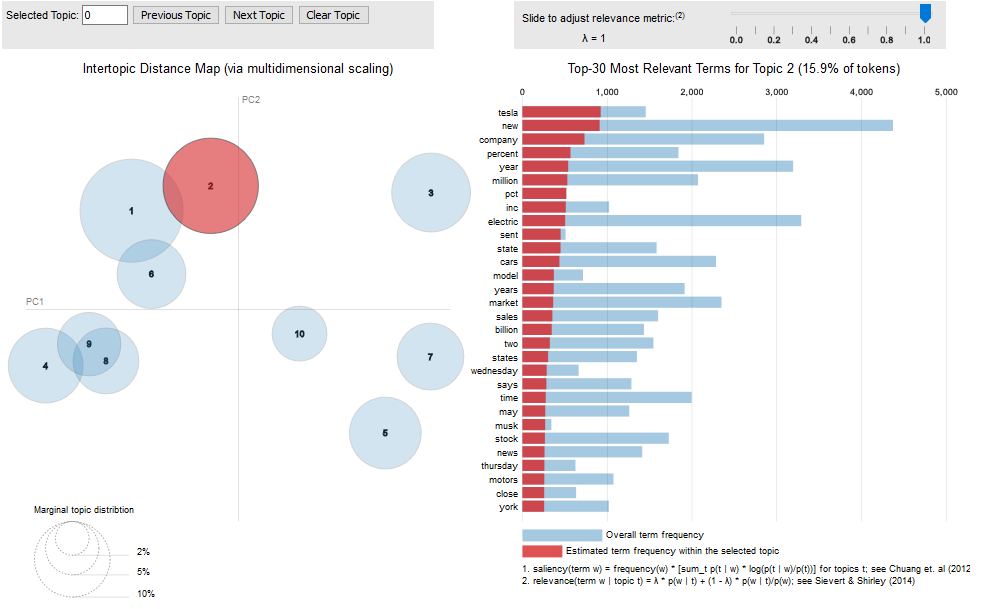
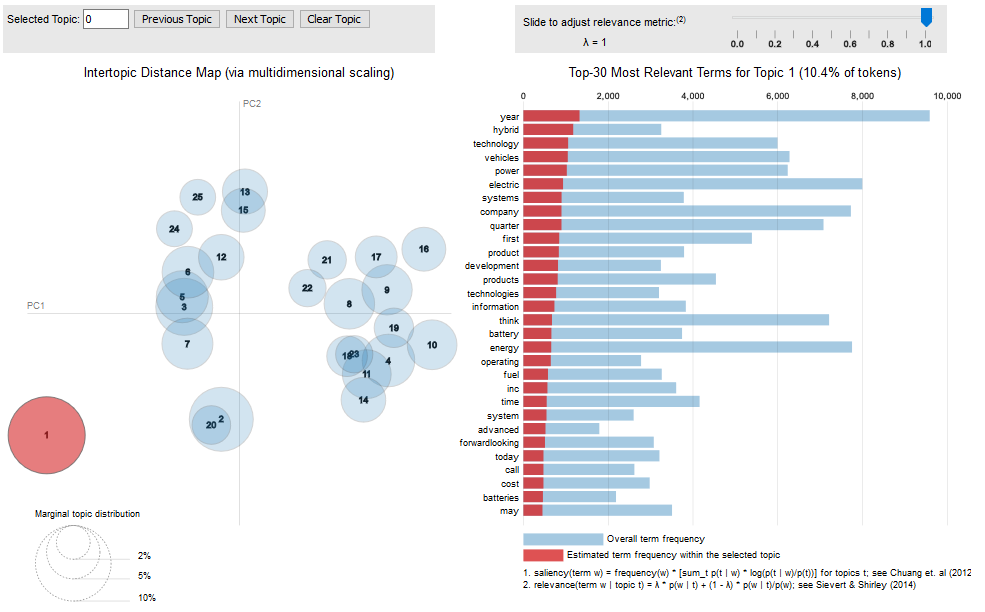
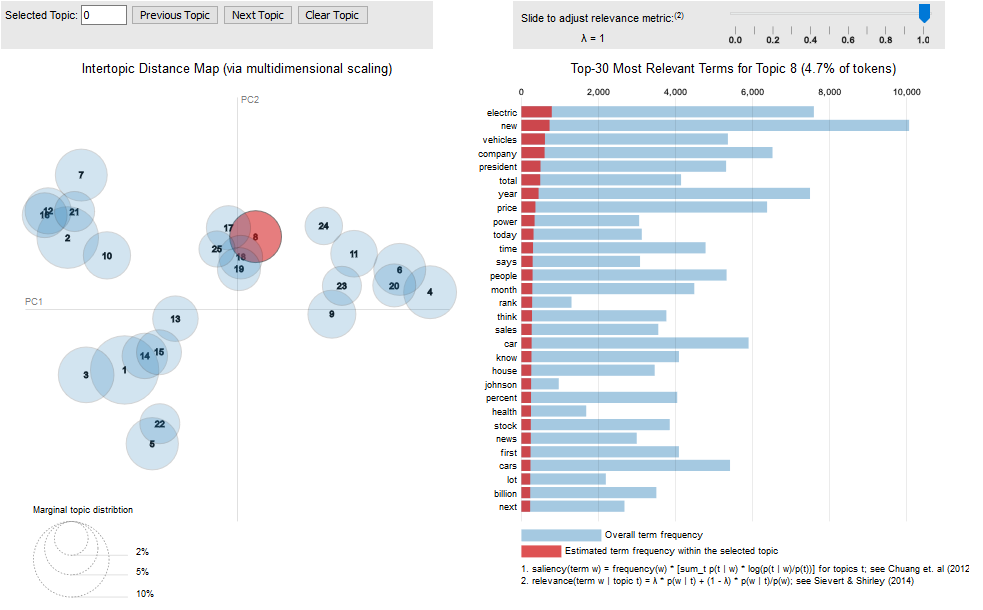
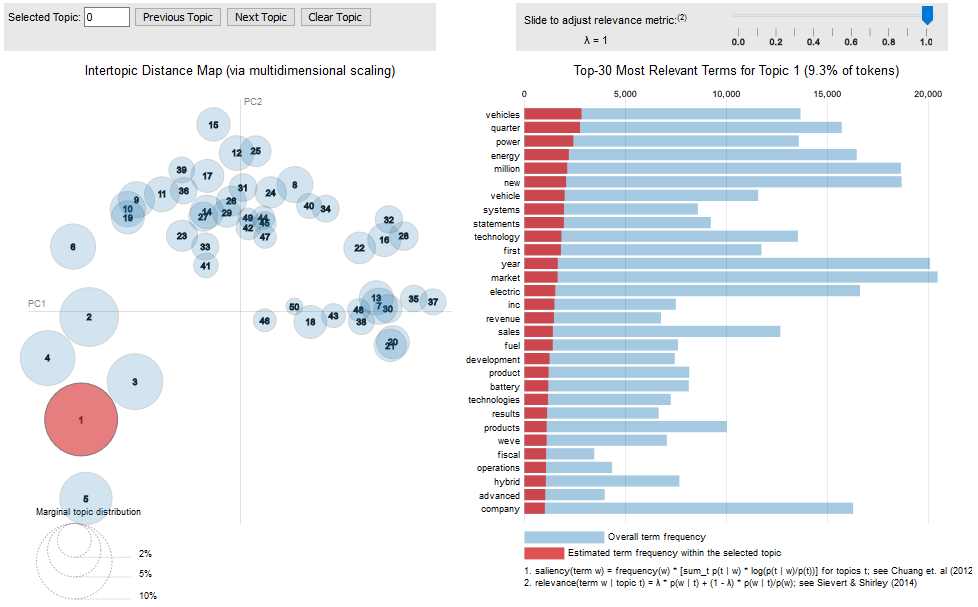
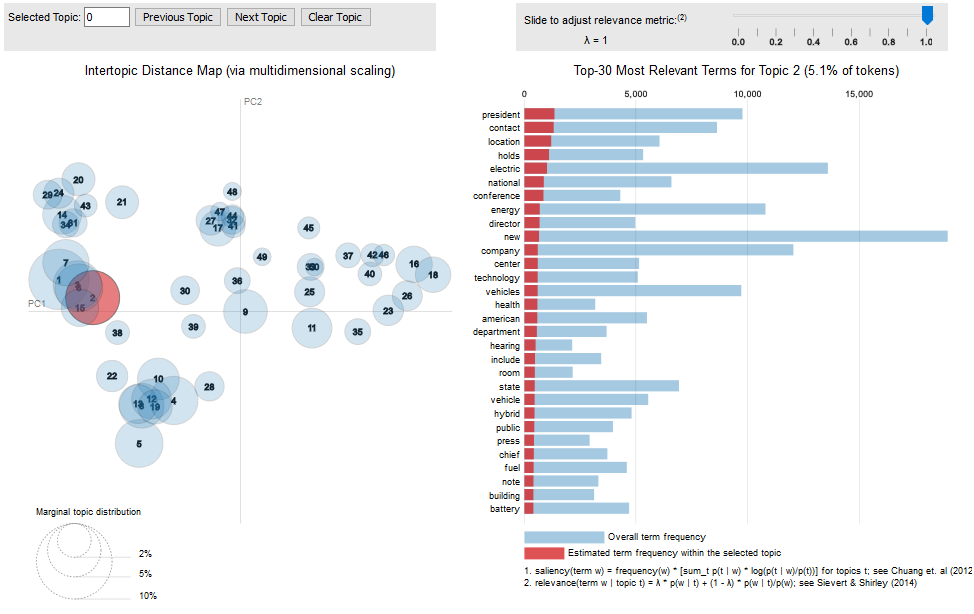
The following URL points to the data with all the output
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2018/Data_LDA.RData?raw=true"))