2017 Workshop at the Academy of Management Annual Meeting
First time setup in R
In order to follow the code developed for the workshop (shown in full below under Workshop example), two pieces of software need to be installed beforehand. The first is R, a free software environment for statistical computing and graphics. The second is RStudio, which is a graphical user interface that goes ‘over’ R, making it more user friendly. It is adamant that R is installed first, and RStudio second.
Before running the code shown below, install R on your system by going to the following page: https://cran.r-project.org/ Here, OS-specific versions of R can be found. For example, by clicking here, you can download the executable for Windows (version 3.4.1 is the latest version at the time of writing). Installation using the default settings should do the trick.
Then, after the installation of R is complete, navigate to the following page: https://www.rstudio.com/ You can download the free version of RStudio on this page, with this link pointing directly to the executable for Windows. Again, the default settings should do the trick.
Then, after these steps are completed, it is advisable to run the following two lines of code in RStudio before coming to the workshop.
if (!require("tm")) install.packages("tm")
if (!require("topicmodels")) install.packages("topicmodels")
These will install the two core packages that we will use in the workshop, and their installation may take some time on the standard conference internet connection. After this is done, you’re all set to participate in the workshop! It is also possible to run the code shown below at home beforehand, but note that the actual topic model takes a LONG time to finish on most PCs.
You can install packages by entering them to your script (you can start a new script on Windows via “Shift+Ctrl+N” or by navigating to “File” –> “New File” –> “R Script”. You can run code by selecting the code and pressing “Ctrl + Enter” or the “Run” button at the top of the script window. Packages can also be installed by navigating to “Packages” (which should be on the right half of your screen), or by selecting “Tools” at the top of your screen and selecting “Install packages” from there.
Workshop example
Abstracts of five journals ——————- Code tested and written for R version 3.4, tm package version 0.7-1, topicmodels package version 0.2-6. Code prepared on May 10, 2017 by Richard Haans (haans@rsm.nl). Data obtained from the Web of Science.
Package installation
### Open the R code of this workshop (needs to be copy-pasted into an R script after loading):
url.show("https://raw.githubusercontent.com/RFJHaans/topicmodeling/master/Data/2017/2017%20AoM%20LDA%20Workshop%20-%20abstracts.R")
# The "tm" package enables the text mining infrastructure that we will use for LDA.
if (!require("tm")) install.packages("tm")
# The "topicmodels" package enables LDA analysis.
if (!require("topicmodels")) install.packages("topicmodels")
Get the data, turn into a corpus, and clean it up
### Load the output of the 200-topic model (we cannot run it during the workshop due to time constraints).
load(url("https://github.com/RFJHaans/topicmodeling/blob/master/Data/2017/LDA200.RData?raw=true"))
### Load data from a URL
data = read.csv(url("https://raw.githubusercontent.com/RFJHaans/topicmodeling/master/Data/2017/ASQ_AMJ_AMR_OS_SMJ.csv"))
### Create a corpus.
corpus = VCorpus((VectorSource(data[, "AB"])))
### Basic cleaning (step-wise)
# We write everything to a new corpus called "corpusclean" so that we do not lose the original data.
# 1) Remove numbers
corpusclean = tm_map(corpus, removeNumbers)
# 2) Remove punctuation
corpusclean = tm_map(corpusclean, removePunctuation)
# 3) Transform all upper-case letters to lower-case.
corpusclean = tm_map(corpusclean, content_transformer(tolower))
# 4) Remove stopwords which do not convey any meaning.
corpusclean = tm_map(corpusclean, removeWords, stopwords("english"))
# this stopword file is at C:\Users\[username]\Documents\R\win-library\[rversion]\tm\stopwords
# i me my myself we our ours ourselves you your yours yourself yourselves he him his himself
# she her hers herself it its itself they them their theirs themselves what which who whom this
# that these those am is are was were be been being have has had having do does did doing would should
# could ought i'm you're he's she's it's we're they're i've you've we've they've i'd you'd he'd she'd we'd
# they'd i'll you'll he'll she'll we'll they'll isn't aren't wasn't weren't hasn't haven't hadn't doesn't
# don't didn't won't wouldn't shan't shouldn't can't cannot couldn't mustn't let's that's who's what's here's
# there's when's where's why's how's a an the and but if or because as until while of at by for with about
# against between into through during before after above below to from up down in out on off over under again
# further then once here there when where why how all any both each few more most other some such no nor
# not only own same so than too very
# 5) And strip whitespace.
corpusclean = tm_map(corpusclean , stripWhitespace)
# See the help of getTransformations for more possibilities, such as stemming.
# To speed up the computation process for this tutorial, I have selected some choice words that were very common:
# We update the corpusclean corpus by removing these words.
corpusclean = tm_map(corpusclean, removeWords, c("also","based","can","data","effect",
"effects","elsevier","evidence","examine",
"find","findings","high","low","higher","lower",
"however","impact","implications","important",
"less","literature","may","model","one","paper",
"provide","research","all rights reserved",
"results","show","studies","study","two","use",
"using","rights","reserved","new","analysis","three",
"associated","firm","firms","copyright","sons","john","ltd","wiley"))
### Adding metadata from the original database
# This needs to be done because transforming things into a corpus only uses the texts.
i = 0
corpusclean = tm_map(corpusclean, function(x) {
i <<- i +1
meta(x, "id") = as.character(data[i,"ID"])
x
})
i = 0
corpusclean = tm_map(corpusclean, function(x) {
i <<- i +1
meta(x, "journal") = as.character(data[i,"SO"])
x
})
# The above is a loop that goes through all files ("i") in the corpus
# and then maps the information of the metadata dataframe
# (the "ID" column, et cetera) to a new piece of metadata in the corpus
# which we also call "id", et cetera.
# This enables making selections of the corpus based on metadata now.
# Let's say we want to only look at articles from the AMJ, then we do the following:
keep = meta(corpusclean, "journal") == "ACADEMY OF MANAGEMENT JOURNAL"
corpus.AMJ = corpusclean[keep]
# We then convert the corpus to a "Document-term-matrix" (dtm)
dtm =DocumentTermMatrix(corpusclean)
dtm
<<DocumentTermMatrix (documents: 1530, terms: 11744)>>
Non-/sparse entries: 89755/17878565
Sparsity : 100%
Maximal term length: 30
Weighting : term frequency (tf)
# dtms are organized with rows being documents and columns being the unique words.
# We can see here that the longest word in the corpus is 30 characters long.
# There are 1530 documents, containing 11744 unique words.
# Let's check out the sixth and seventh abstract in our data (rows in the DTM) and the 4000th to 4010th words:
inspect(dtm[6:7,4000:4010])
Terms
Docs facilitation facilitative facilitators facilities facility facing fact factbased factions facto
ID6 0 0 0 0 0 1 0 0 0 0
ID7 0 0 0 0 0 0 1 0 0 0
# Abstract six contains "facing", once. Abstract seven contains "fact" once.
# The step below is done to ensure that after removing various words, no documents are left empty
# (LDA does not know how to deal with empty documents).
rowTotals = apply(dtm , 1, sum)
# This sums up the total number of words in each of the documents, e.g.:
rowTotals[1:10]
# shows the number of words for the first ten abstracts.
ID1 ID2 ID3 ID4 ID5 ID6 ID7 ID8 ID9 ID10
40 73 85 111 103 98 97 91 82 124
# Then, we keep only those documents where the sum of words is greater than zero.
dtm = dtm[rowTotals> 0, ]
dtm
# Shows no abstracts were lost due to our cleaning.
<<DocumentTermMatrix (documents: 1530, terms: 11744)>>
Non-/sparse entries: 89755/17878565
Sparsity : 100%
Maximal term length: 30
Weighting : term frequency (tf)
Infrequent words and frequent words
# Next, we will assess which words are most frequent:
highfreq500 = findFreqTerms(dtm,500,Inf)
# This creates a vector containing words from the dtm that occur 500 or more time (100 to infinity times)
# In the top-right window, we can see that there are six words occurring more than 500 times.
# Let's see what words these are:
highfreq500
[1] "knowledge" "organizational" "organizations" "performance" "social"
[6] "theory"
# We can create a smaller dtm that makes the following two selections on the words in the corpus:
# This greatly saves on computing time, but infrequent words may also provide valuable information,
# so one needs to be careful when selecting cut-off values.
# 1) Keep only those words that occur more than 50 times.
minoccur = 50
# 2) Keep only those words that occur in at least 10 of the documents.
mindocs = 10
# Note that this is completed on the corpus, not the DTM.
smalldtm = DocumentTermMatrix(corpusclean, control=list(dictionary = findFreqTerms(dtm,minoccur,Inf),
bounds = list(global = c(mindocs,Inf))))
rowTotals = apply(smalldtm , 1, sum)
smalldtm = smalldtm[rowTotals> 0, ]
smalldtm
<<DocumentTermMatrix (documents: 1530, terms: 518)>>
Non-/sparse entries: 41211/751329
Sparsity : 95%
Maximal term length: 19
Weighting : term frequency (tf)
# This reduces the number of words to 518 (from 11744, so a very large reduction).
# No abstracts are removed, however.
LDA: Running the model
# We first fix the random seed for future replication.
SEED = 123456789
# Here we define the number of topics to be estimated. I find fifty provides decent results, while much lower
# leads to messy topics with little variation.
# However, little theory or careful investigation went into this so be wary.
k = 200
# We then create a variable which captures the starting time of this particular model.
t1_LDA200 = Sys.time()
# And then we run a LDA model with 200 topics (k = 200).
# Note that the input is the dtm
LDA200 = LDA(dtm, k = k, control = list(seed = SEED))
# The default command uses the VEM algorithm, but an alternative is Gibbs sampling (see the documentation of the topicmodels package)
# And we create a variable capturing the end time of this model.
t2_LDA200 = Sys.time()
# We can then check the time difference to see how long the model took.
t2_LDA200 - t1_LDA200
Time difference of 23.0202 mins
k2 = 20
# We then create a variable which captures the starting time of this particular model.
t1_LDA20 = Sys.time()
LDA20 = LDA(smalldtm, k = k2, control = list(seed = SEED))
t2_LDA20 = Sys.time()
t2_LDA20 - t1_LDA20
Time difference of 11.29924 secs
LDA: The output
# We then create a variable that captures the top ten terms assigned to the 15-topic model:
topics_LDA200 = terms(LDA200, 10)
# We can write the results of the topics to a .csv file as follows:
# write.table(topics_LDA200, file = "200_topics", sep=',',row.names = FALSE)
# This writes to the directory of the .R script, but the 'file = ' can be changed to any directory.
# And show the results:
topics_LDA200
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Topic 6
[1,] "efforts" "social" "family" "experience" "embeddedness" "ceo"
[2,] "organizations" "exchange" "venture" "learning" "network" "ceos"
[3,] "activities" "justice" "control" "performance" "knowledge" "support"
[4,] "work" "perceptions" "markets" "prior" "countries" "corporate"
[5,] "behavioral" "behavior" "ownership" "relational" "transfer" "management"
Topic 7 Topic 8 Topic 9 Topic 10 Topic 11
[1,] "control" "relationship" "incentives" "cognitive" "communication"
[2,] "organizational" "strategy" "value" "capabilities" "processes"
[3,] "attention" "country" "network" "processes" "process"
[4,] "organizations" "partners" "relationships" "control" "coordination"
[5,] "technology" "characteristics" "formal" "managerial" "organizational"
Topic 12 Topic 13 Topic 14 Topic 15 Topic 16 Topic 17
[1,] "strategic" "market" "events" "team" "change" "knowledge"
[2,] "knowledge" "value" "across" "creativity" "institutional" "innovation"
[3,] "public" "growth" "influence" "teams" "field" "external"
[4,] "political" "negative" "positive" "individual" "actors" "creativity"
[5,] "private" "will" "focus" "member" "organizational" "ties"
Topic 18 Topic 19 Topic 20 Topic 21 Topic 22
[1,] "organizational" "exit" "team" "performance" "technology"
[2,] "organizations" "work" "structure" "social" "knowledge"
[3,] "prior" "analysts" "exchange" "diversity" "initial"
[4,] "search" "boundary" "learning" "relationship" "learning"
[5,] "relationship" "types" "relationship" "team" "capacity"
Topic 23 Topic 24 Topic 25 Topic 26 Topic 27 Topic 28
[1,] "process" "innovation" "control" "target" "experience" "organizational"
[2,] "organizations" "corporate" "organizational" "acquisition" "role" "units"
[3,] "attention" "network" "acquisitions" "acquisitions" "process" "unit"
[4,] "activities" "product" "performance" "market" "groups" "strategies"
[5,] "entrepreneurs" "industry" "managerial" "focal" "knowledge" "relationship"
Topic 29 Topic 30 Topic 31 Topic 32 Topic 33 Topic 34
[1,] "knowledge" "collective" "employees" "network" "ties" "performance"
[2,] "innovation" "community" "work" "ties" "networks" "exploration"
[3,] "challenges" "management" "employee" "networks" "choices" "search"
[4,] "many" "context" "time" "social" "executives" "problem"
[5,] "form" "knowledge" "related" "structure" "make" "information"
Topic 35 Topic 36 Topic 37 Topic 38 Topic 39
[1,] "attention" "mechanisms" "media" "employee" "performance"
[2,] "theory" "theoretical" "voice" "entrepreneurship" "relationships"
[3,] "organizations" "different" "product" "knowledge" "ceo"
[4,] "organizational" "orientation" "managerial" "events" "influence"
[5,] "processes" "strategies" "control" "behavior" "types"
Topic 40 Topic 41 Topic 42 Topic 43 Topic 44
[1,] "social" "leadership" "events" "mechanisms" "organizational"
[2,] "performance" "behaviors" "organizational" "organizations" "theory"
[3,] "justice" "leaders" "work" "theory" "routines"
[4,] "diversity" "work" "framework" "agency" "business"
[5,] "corporate" "performance" "creative" "organizational" "capabilities"
Topic 45 Topic 46 Topic 47 Topic 48 Topic 49
[1,] "integration" "knowledge" "strategy" "learning" "innovation"
[2,] "capital" "transfer" "fit" "organizational" "technology"
[3,] "boundaries" "network" "past" "value" "network"
[4,] "process" "boundary" "innovation" "theory" "organizations"
[5,] "innovation" "organizational" "develop" "processes" "networks"
Topic 50 Topic 51 Topic 52 Topic 53 Topic 54
[1,] "market" "performance" "ties" "networks" "identity"
[2,] "governance" "product" "logics" "network" "identities"
[3,] "capabilities" "strategic" "building" "groups" "organizational"
[4,] "companies" "development" "market" "group" "work"
[5,] "executives" "case" "categories" "ties" "individuals"
Topic 55 Topic 56 Topic 57 Topic 58 Topic 59
[1,] "organizational" "social" "complexity" "uncertainty" "strategy"
[2,] "risk" "theory" "task" "different" "affect"
[3,] "social" "models" "organizational" "choice" "management"
[4,] "making" "organizations" "degree" "governance" "top"
[5,] "perspective" "institutional" "complex" "structure" "role"
Topic 60 Topic 61 Topic 62 Topic 63 Topic 64 Topic 65
[1,] "feedback" "entry" "power" "team" "institutional" "different"
[2,] "performance" "industry" "source" "entrepreneurial" "local" "argue"
[3,] "creative" "technologies" "ownership" "teams" "logics" "performance"
[4,] "workers" "power" "theory" "changes" "search" "among"
[5,] "internal" "business" "management" "products" "investment" "private"
Topic 66 Topic 67 Topic 68 Topic 69 Topic 70 Topic 71
[1,] "performance" "performance" "activities" "performance" "work" "information"
[2,] "coordination" "social" "performance" "leader" "change" "social"
[3,] "team" "capabilities" "learning" "negative" "action" "status"
[4,] "teams" "quality" "activity" "actions" "mechanisms" "within"
[5,] "management" "status" "patterns" "theory" "practices" "individuals"
Topic 72 Topic 73 Topic 74 Topic 75 Topic 76 Topic 77
[1,] "search" "voice" "institutional" "women" "organizations" "decision"
[2,] "likelihood" "workplace" "institutions" "men" "organizational" "making"
[3,] "engagement" "employees" "business" "gender" "success" "ethical"
[4,] "joint" "outcomes" "countries" "social" "framework" "group"
[5,] "models" "identification" "ownership" "differences" "strategy" "process"
Topic 78 Topic 79 Topic 80 Topic 81 Topic 82
[1,] "turnover" "design" "communication" "job" "pay"
[2,] "performance" "products" "team" "satisfaction" "managers"
[3,] "job" "technological" "members" "relationship" "corporate"
[4,] "employees" "product" "managers" "turnover" "social"
[5,] "theory" "industry" "teams" "individual" "discuss"
Topic 83 Topic 84 Topic 85 Topic 86 Topic 87
[1,] "logic" "employees" "organizational" "institutional" "alliances"
[2,] "field" "performance" "employee" "differences" "knowledge"
[3,] "organizations" "likely" "employees" "environments" "governance"
[4,] "social" "negative" "individuals" "theory" "reputation"
[5,] "logics" "job" "leadership" "legitimacy" "alliance"
Topic 88 Topic 89 Topic 90 Topic 91 Topic 92 Topic 93
[1,] "market" "industry" "market" "directors" "entrepreneurs" "team"
[2,] "ties" "corporate" "product" "board" "information" "teams"
[3,] "value" "ventures" "complementary" "boards" "product" "members"
[4,] "exit" "venture" "knowledge" "corporate" "search" "time"
[5,] "form" "reputation" "exploration" "governance" "actions" "motivation"
Topic 94 Topic 95 Topic 96 Topic 97 Topic 98
[1,] "theory" "organizational" "creative" "learning" "decision"
[2,] "practice" "theory" "decisions" "foreign" "makers"
[3,] "characteristics" "executives" "managers" "entry" "performance"
[4,] "process" "employee" "strategic" "industry" "information"
[5,] "organizational" "units" "relational" "interorganizational" "strategic"
Topic 99 Topic 100 Topic 101 Topic 102 Topic 103 Topic 104
[1,] "organizational" "ceos" "parties" "corporate" "capability" "projects"
[2,] "work" "ceo" "third" "organizational" "capabilities" "within"
[3,] "trust" "will" "positive" "managers" "dynamic" "theory"
[4,] "institutional" "performance" "perceived" "attention" "development" "investments"
[5,] "peers" "theory" "social" "industries" "resources" "economic"
Topic 105 Topic 106 Topic 107 Topic 108 Topic 109
[1,] "work" "performance" "logics" "performance" "networks"
[2,] "interactions" "costs" "institutional" "managers" "network"
[3,] "online" "diversification" "organizational" "among" "social"
[4,] "team" "search" "different" "decisions" "entry"
[5,] "coordination" "market" "outcomes" "projects" "structure"
Topic 110 Topic 111 Topic 112 Topic 113 Topic 114
[1,] "performance" "industry" "theory" "attention" "women"
[2,] "status" "behavioral" "management" "organizational" "gender"
[3,] "groups" "learning" "theories" "evolution" "men"
[4,] "group" "subsequent" "framework" "capabilities" "employees"
[5,] "work" "acquisition" "approach" "management" "psychological"
Topic 115 Topic 116 Topic 117 Topic 118 Topic 119
[1,] "innovation" "work" "diversification" "development" "organizations"
[2,] "industry" "framework" "international" "organizational" "community"
[3,] "business" "dimensions" "relationship" "justice" "relationships"
[4,] "capital" "within" "financial" "routines" "organizational"
[5,] "target" "understanding" "product" "time" "social"
Topic 120 Topic 121 Topic 122 Topic 123 Topic 124
[1,] "alliance" "status" "status" "decisions" "knowledge"
[2,] "alliances" "performance" "market" "regulatory" "performance"
[3,] "partners" "negative" "positive" "institutional" "capabilities"
[4,] "prior" "individuals" "organization" "differences" "external"
[5,] "within" "social" "reputation" "foreign" "learning"
Topic 125 Topic 126 Topic 127 Topic 128 Topic 129
[1,] "institutional" "exchange" "csr" "learning" "conflict"
[2,] "capabilities" "partners" "ceos" "organizations" "focus"
[3,] "reputation" "relationships" "political" "organizational" "experience"
[4,] "complexity" "social" "corporate" "collective" "regulatory"
[5,] "decision" "prior" "stakeholder" "status" "process"
Topic 130 Topic 131 Topic 132 Topic 133 Topic 134 Topic 135
[1,] "performance" "social" "performance" "capabilities" "innovation" "target"
[2,] "decision" "women" "approaches" "market" "performance" "strategy"
[3,] "makers" "men" "resources" "markets" "financial" "first"
[4,] "context" "organization" "competitive" "likely" "knowledge" "corporate"
[5,] "employees" "interactions" "empirical" "costs" "changes" "type"
Topic 136 Topic 137 Topic 138 Topic 139 Topic 140 Topic 141
[1,] "family" "capital" "alliance" "ideas" "work" "corporate"
[2,] "strategic" "human" "alliances" "diversity" "control" "governance"
[3,] "behavioral" "categories" "partners" "investments" "system" "stakeholders"
[4,] "management" "market" "learning" "group" "resources" "organizational"
[5,] "strategy" "employee" "value" "creative" "organizations" "framework"
Topic 142 Topic 143 Topic 144 Topic 145 Topic 146
[1,] "work" "groups" "teams" "behavioral" "across"
[2,] "support" "power" "services" "family" "external"
[3,] "develop" "financial" "strategic" "superior" "collaboration"
[4,] "cognitive" "group" "diverse" "strategy" "practices"
[5,] "role" "business" "diversity" "performance" "levels"
Topic 147 Topic 148 Topic 149 Topic 150 Topic 151
[1,] "performance" "ethical" "acquisition" "focus" "analysts"
[2,] "members" "moral" "growth" "international" "diversification"
[3,] "collective" "organizations" "risk" "ceos" "competitive"
[4,] "family" "influence" "market" "performance" "future"
[5,] "individual" "leadership" "test" "early" "status"
Topic 152 Topic 153 Topic 154 Topic 155 Topic 156
[1,] "social" "job" "cultural" "field" "knowledge"
[2,] "individuals" "search" "organizational" "theory" "management"
[3,] "role" "jobs" "organization" "innovations" "learning"
[4,] "influence" "performance" "practices" "capabilities" "organizational"
[5,] "managers" "organizations" "organizations" "capital" "routines"
Topic 157 Topic 158 Topic 159 Topic 160 Topic 161 Topic 162
[1,] "opportunities" "business" "options" "technology" "types" "social"
[2,] "process" "diversity" "performance" "learning" "positive" "markets"
[3,] "sources" "positive" "technology" "organizational" "concept" "online"
[4,] "within" "core" "logic" "experiences" "better" "behaviors"
[5,] "external" "managerial" "markets" "knowledge" "used" "community"
Topic 163 Topic 164 Topic 165 Topic 166 Topic 167 Topic 168
[1,] "development" "performance" "ceo" "decisions" "values" "jobs"
[2,] "power" "social" "compensation" "time" "performance" "dependence"
[3,] "technologies" "companies" "directors" "experience" "work" "power"
[4,] "positive" "economic" "outside" "influence" "management" "job"
[5,] "address" "relationship" "risk" "communication" "identity" "theory"
Topic 169 Topic 170 Topic 171 Topic 172 Topic 173
[1,] "institutional" "fit" "organizational" "network" "performance"
[2,] "entrepreneurship" "performance" "adoption" "collaboration" "organizational"
[3,] "organizational" "services" "practice" "actors" "organizations"
[4,] "innovation" "institutional" "status" "knowledge" "individuals"
[5,] "analysts" "products" "organizations" "social" "innovation"
Topic 174 Topic 175 Topic 176 Topic 177 Topic 178 Topic 179
[1,] "resource" "environmental" "decision" "activities" "organizational" "benefits"
[2,] "market" "teams" "knowledge" "dependence" "managers" "strategy"
[3,] "performance" "team" "decisions" "investment" "identification" "context"
[4,] "governance" "performance" "making" "communication" "members" "mechanisms"
[5,] "political" "information" "foreign" "social" "social" "performance"
Topic 180 Topic 181 Topic 182 Topic 183 Topic 184
[1,] "leadership" "resources" "team" "strategic" "business"
[2,] "leaders" "institutional" "creative" "actions" "systems"
[3,] "theory" "market" "innovation" "network" "existing"
[4,] "behavior" "complementary" "development" "actors" "relational"
[5,] "leader" "context" "knowledge" "organizational" "investment"
Topic 185 Topic 186 Topic 187 Topic 188 Topic 189
[1,] "employees" "organizational" "relationship" "organizational" "change"
[2,] "behaviors" "organizations" "political" "innovation" "strategic"
[3,] "opportunities" "forms" "psychological" "technology" "organizational"
[4,] "opportunity" "practices" "need" "technological" "develop"
[5,] "voice" "organization" "professional" "will" "distinct"
Topic 190 Topic 191 Topic 192 Topic 193 Topic 194 Topic 195
[1,] "value" "market" "work" "performance" "identity" "team"
[2,] "performance" "competitive" "ties" "business" "organizational" "members"
[3,] "competitive" "industry" "relationships" "unit" "identification" "among"
[4,] "strategy" "advantage" "strategies" "leadership" "social" "performance"
[5,] "advantage" "resource" "outcomes" "team" "organizations" "teams"
Topic 196 Topic 197 Topic 198 Topic 199 Topic 200
[1,] "influence" "groups" "group" "resources" "knowledge"
[2,] "political" "online" "routines" "resource" "field"
[3,] "association" "routines" "ties" "portfolio" "practice"
[4,] "performance" "competition" "identity" "value" "personal"
[5,] "public" "innovation" "groups" "communication" "differences"
# We can also look at the 20-topic model's topics:
topics_LDA20 = terms(LDA20, 10)
# And show the results:
topics_LDA20
# How to show term weights:
word_assignments200 <- t(posterior(LDA200)[["terms"]])
word_assignments200[1:10,1:10]
1 2 3 4 5 6 7 8 9 10
ability 1.003658e-110 2.402186e-03 4.524415e-119 2.529326e-03 4.519954e-03 2.650128e-26 2.189112e-217 5.126056e-119 7.675248e-03 3.162048e-03
access 2.890976e-119 1.803954e-119 6.775001e-267 1.872564e-119 2.681844e-80 1.362547e-119 2.844907e-03 2.806136e-119 1.093941e-305 1.889166e-110
account 6.454202e-03 2.402186e-03 2.525859e-119 3.720076e-44 2.064195e-119 1.389545e-119 3.713690e-88 2.861738e-119 3.174732e-119 2.160706e-119
acquisition 2.260776e-119 1.410712e-119 3.309212e-267 1.464367e-119 3.486398e-107 4.915035e-220 1.670706e-119 2.194431e-119 2.434440e-119 1.656867e-119
acquisitions 1.453408e-119 1.882662e-194 1.245177e-119 2.032038e-194 2.941731e-03 2.026206e-311 2.670178e-194 1.410756e-119 1.565053e-119 1.065277e-119
across 8.255325e-03 1.357002e-29 4.557410e-03 9.262651e-222 9.999588e-03 3.090933e-119 1.267400e-44 3.736716e-03 4.189305e-123 2.172829e-03
action 3.849690e-03 1.987888e-119 1.709013e-193 2.063494e-119 2.230468e-119 1.501475e-119 2.420920e-67 3.092255e-119 2.743137e-82 9.900292e-58
actions 4.556416e-119 6.600636e-83 3.903614e-119 2.951316e-119 2.640163e-03 2.147487e-119 1.733362e-76 7.671477e-03 4.906422e-119 1.609519e-132
activities 2.136604e-02 2.440501e-119 3.350746e-119 7.728052e-03 2.738313e-119 4.171621e-123 5.894147e-03 3.736716e-03 4.211526e-119 1.462414e-02
activity 3.945952e-87 1.705369e-119 2.341428e-119 2.117941e-02 1.913474e-119 1.288085e-119 3.773279e-267 3.124542e-93 2.942923e-119 9.183462e-194
# Let's now create a file containing the topic loadings for all articles:
gammaDF_LDA200 = as.data.frame(LDA200@gamma)
# This creates a dataframe containing for every row the articles and for every column the per-topic loading.
gammaDF_LDA200$ID = smalldtm$dimnames$Docs
# We add the ID from the metadata for merging with the metadata file. Of course
# any other type of data can be added.
# If we are not necessarily interested in using the full range of topic loadings,
# but only in keeping those loadings that exceed a certain threshold,
# then we can use the code below:
majortopics = topics(LDA200, threshold = 0.3)
majortopics = as.data.frame(vapply(majortopics,
paste, collapse = ", ", character(1L)))
colnames(majortopics) = "topic"
majortopics$topic = sub("^$", 0, majortopics$topic)
# Here, we state that we want to show all topics that load greater than 0.3, per paper.
# Of course, the higher the threshold, the fewer topics will be selected per paper.
# The flattening (the second and third line) is done to clean this column up (from e.g. "c(1,5,7)" to "1,5,7")
# The fourth line replaces those without a topic with the value zero.
# The last line renames the column.
# Some abstracts may have no topics assigned to them.
# NOTE: It will report the topics in a sequential manner - the first topic in this list is not
# necessarily the most important topic.
# We can also select the highest loading topic for every paper by changing the threshold-subcommand
# to k = (k refers to the number of highest loading topics per paper):
highest = as.data.frame(data$SO)
# I first make a column containing the journal, since we're going to do some follow-up checks on this dataframe.
highest$maintopic = topics(LDA200, k = 1)
# I then add the highest loading topic of each abstract. We can do this because the order of the data is identical.
# Otherwise, we'd need to match the two using the ID variable (e.g. if some abstracts had been removed due to cleaning).
Plotting topic usage across journals and over time
# We cross-tabulate journals and highest loading topics
crosstabtable = table(highest)
crosstabtable
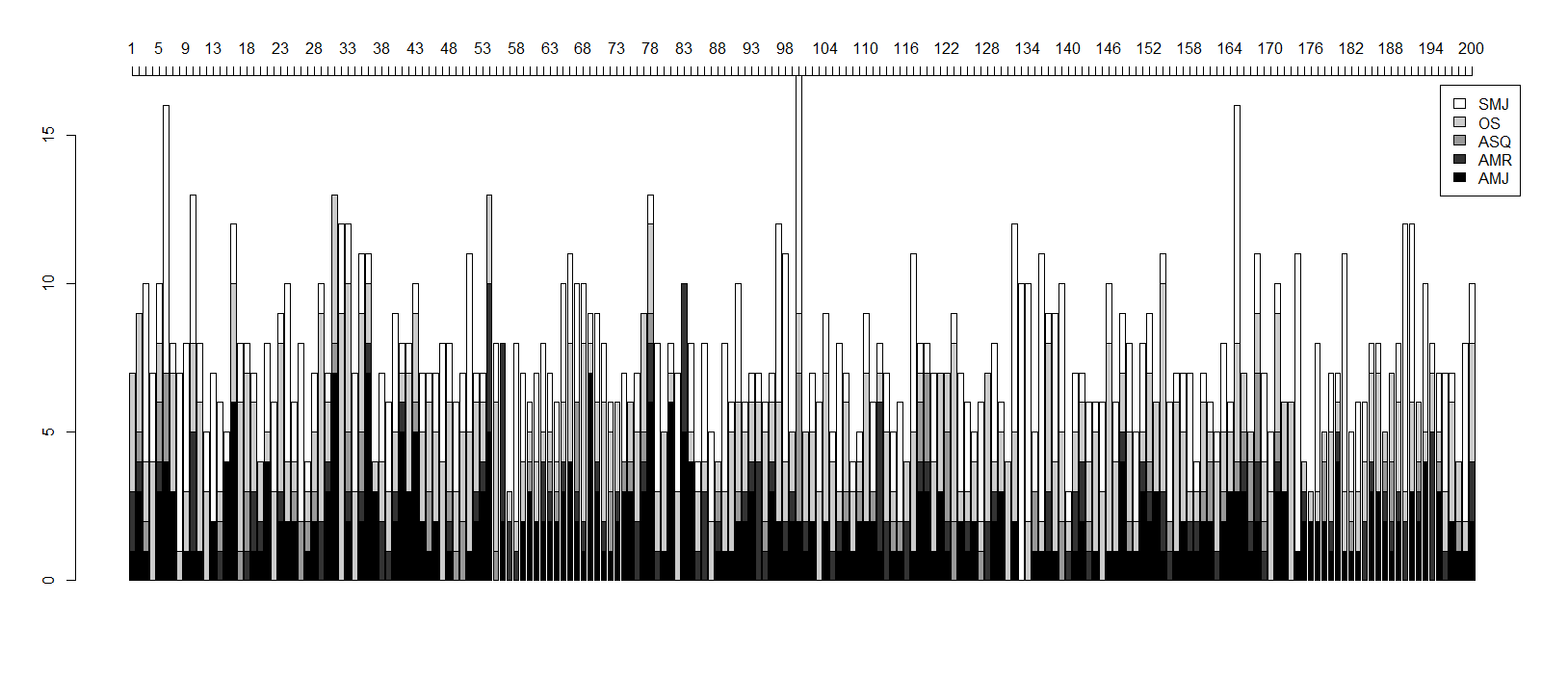
# The following topics are most distinctive for each journal:
# AMJ: Topic 69 (distance = 6.5) --> performance, leader, negative, actions, theory
# AMR: Topic 56 (distance = 5.5) --> social, theory, models, organizations, institutional
# ASQ: Topic 100 (distance = 2) --> ceos, ceo, will, performance, theory
# OS: Topic 32 (distance = 8.25) --> network, ties, networks, social, structure
# SMJ: Topic 133 (distance = 10) --> capabilities, market, markets, likely, costs
maintopic
data$SO 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ACADEMY OF MANAGEMENT JOURNAL 1 3 1 0 3 4 3 0 1 1 1 0 2 0 4 6 0 0 1 1
ACADEMY OF MANAGEMENT REVIEW 2 1 0 0 1 0 0 0 0 4 0 0 0 1 0 0 0 1 2 1
ADMINISTRATIVE SCIENCE QUARTERLY 0 1 1 0 2 3 0 0 0 0 0 0 0 1 0 0 1 2 0 0
ORGANIZATION SCIENCE 4 4 2 4 2 0 4 1 2 3 5 3 0 1 0 4 5 4 3 2
STRATEGIC MANAGEMENT JOURNAL 0 0 6 3 2 9 1 6 5 5 2 2 5 3 1 2 2 1 1 0
maintopic
data$SO 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
ACADEMY OF MANAGEMENT JOURNAL 4 0 2 2 2 0 1 2 0 3 7 0 2 0 2 7 3 0 0 2
ACADEMY OF MANAGEMENT REVIEW 0 0 1 0 0 0 0 0 2 1 0 0 1 0 1 1 0 2 1 1
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 0 0 1 2 1 1 0 0 1 0 2 0 2 0 0 0 0 0
ORGANIZATION SCIENCE 1 3 5 2 1 0 1 2 7 2 5 9 5 3 4 2 1 2 2 2
STRATEGIC MANAGEMENT JOURNAL 3 3 1 6 2 6 1 2 1 1 0 3 2 4 2 1 0 3 3 4
maintopic
data$SO 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
ACADEMY OF MANAGEMENT JOURNAL 5 3 5 2 1 2 0 1 0 0 1 2 3 5 0 2 0 0 2 3
ACADEMY OF MANAGEMENT REVIEW 1 0 0 0 0 0 0 1 0 0 0 1 1 5 0 6 2 1 0 0
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 1 0 2 0 0 1 1 2 0 0 0 0 1 0 0 0 0 1
ORGANIZATION SCIENCE 1 4 3 3 3 3 4 3 2 3 4 3 2 3 5 0 1 1 2 1
STRATEGIC MANAGEMENT JOURNAL 1 1 1 2 1 2 4 2 3 2 6 1 1 0 2 0 0 6 3 1
maintopic
data$SO 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
ACADEMY OF MANAGEMENT JOURNAL 2 2 2 2 3 4 2 1 7 3 1 1 2 3 3 0 3 6 0 1
ACADEMY OF MANAGEMENT REVIEW 0 2 1 0 1 0 1 1 0 1 1 0 1 0 0 2 1 2 1 0
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 1 1 0 0 3 0 0 0 0 2 0 1 1 0 1 1 0 0
ORGANIZATION SCIENCE 2 1 1 1 2 4 0 6 1 2 4 2 3 0 2 3 4 3 2 4
STRATEGIC MANAGEMENT JOURNAL 3 3 2 2 4 3 4 2 1 3 2 1 0 3 0 2 0 1 5 0
maintopic
data$SO 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
ACADEMY OF MANAGEMENT JOURNAL 6 0 5 4 0 0 0 1 1 1 2 2 3 0 0 3 2 1 2
ACADEMY OF MANAGEMENT REVIEW 0 0 5 0 1 3 0 1 0 0 0 1 1 4 1 1 0 1 1
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0 0
ORGANIZATION SCIENCE 1 3 0 1 2 1 2 1 2 4 3 2 2 2 3 2 4 2 2
STRATEGIC MANAGEMENT JOURNAL 1 4 0 3 1 4 3 0 5 1 4 1 1 1 1 1 6 7 0
maintopic
data$SO 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114
ACADEMY OF MANAGEMENT JOURNAL 2 1 2 0 2 0 1 2 1 2 2 2 1 0 1
ACADEMY OF MANAGEMENT REVIEW 0 1 0 0 0 1 1 0 0 0 0 0 5 2 0
ADMINISTRATIVE SCIENCE QUARTERLY 5 0 0 0 0 0 0 1 0 1 0 1 0 0 1
ORGANIZATION SCIENCE 2 3 3 3 5 3 1 3 2 1 5 0 1 3 1
STRATEGIC MANAGEMENT JOURNAL 8 0 2 3 2 1 5 1 1 1 2 3 1 2 2
maintopic
data$SO 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129
ACADEMY OF MANAGEMENT JOURNAL 1 0 1 3 3 1 3 1 0 2 1 2 0 0 2
ACADEMY OF MANAGEMENT REVIEW 0 2 0 1 1 0 0 1 0 0 1 0 0 2 1
ADMINISTRATIVE SCIENCE QUARTERLY 1 0 0 2 3 0 0 3 2 0 0 0 1 0 0
ORGANIZATION SCIENCE 0 2 4 1 0 3 4 2 6 1 1 2 1 5 1
STRATEGIC MANAGEMENT JOURNAL 4 0 6 1 1 3 0 0 1 4 3 1 4 0 4
maintopic
data$SO 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144
ACADEMY OF MANAGEMENT JOURNAL 3 0 2 0 0 1 1 1 1 0 0 1 2 0 1
ACADEMY OF MANAGEMENT REVIEW 0 0 0 0 0 0 0 2 0 0 1 2 2 1 0
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 0 0 0 2 0 0 0 2 0 0 0 1 0
ORGANIZATION SCIENCE 2 4 3 0 2 0 1 5 3 3 1 2 2 2 4
STRATEGIC MANAGEMENT JOURNAL 1 0 7 10 8 2 9 1 5 5 1 2 1 2 1
maintopic
data$SO 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
ACADEMY OF MANAGEMENT JOURNAL 0 1 1 4 1 1 3 2 3 1 0 1 2 1 1
ACADEMY OF MANAGEMENT REVIEW 0 0 0 1 0 0 1 1 0 2 1 0 0 1 1
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0
ORGANIZATION SCIENCE 3 7 3 2 3 1 1 3 3 7 0 5 3 1 1
STRATEGIC MANAGEMENT JOURNAL 3 2 2 2 3 3 3 2 0 1 4 1 2 4 1
maintopic
data$SO 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174
ACADEMY OF MANAGEMENT JOURNAL 2 2 0 2 3 3 3 1 2 0 0 3 3 0 1
ACADEMY OF MANAGEMENT REVIEW 0 0 1 0 0 0 1 1 2 1 0 1 0 0 0
ADMINISTRATIVE SCIENCE QUARTERLY 1 2 0 1 0 1 1 2 3 1 0 1 0 0 0
ORGANIZATION SCIENCE 3 1 3 2 2 4 2 1 2 2 3 4 3 6 0
STRATEGIC MANAGEMENT JOURNAL 1 1 1 3 1 8 0 0 2 3 2 1 0 0 10
maintopic
data$SO 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189
ACADEMY OF MANAGEMENT JOURNAL 2 2 2 2 1 4 1 1 1 0 3 3 2 1 2
ACADEMY OF MANAGEMENT REVIEW 1 0 0 0 1 1 0 0 0 2 1 0 1 1 1
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 0 2 0 0 0 1 0 0 0 0 1 2 0
ORGANIZATION SCIENCE 1 1 1 1 3 1 2 1 2 2 3 4 1 3 3
STRATEGIC MANAGEMENT JOURNAL 0 0 5 0 2 1 8 2 3 2 1 1 0 0 2
maintopic
data$SO 190 191 192 193 194 195 196 197 198 199 200
ACADEMY OF MANAGEMENT JOURNAL 0 3 2 4 0 3 0 2 1 1 2
ACADEMY OF MANAGEMENT REVIEW 2 0 1 0 5 0 1 0 0 0 2
ADMINISTRATIVE SCIENCE QUARTERLY 0 0 1 0 0 1 0 0 1 0 0
ORGANIZATION SCIENCE 1 3 2 1 2 1 2 4 2 1 4
STRATEGIC MANAGEMENT JOURNAL 9 6 0 5 1 2 4 1 0 6 2
# And create a barplot (first line) with ticks at every X value (second line)
bar1 <- barplot(crosstabtable,legend.text = c("AMJ", "AMR","ASQ","OS","SMJ"),col = c("gray0","gray20","gray60","gray80","gray100"), axisnames=FALSE)
axis(3,at=bar1,labels=seq(1,200,by=1))
# We can also check only for the SMJ, for example.
bar2 <-barplot(crosstabtable["ACADEMY OF MANAGEMENT JOURNAL",], axisnames=FALSE)
axis(3,at=bar2,labels=seq(1,200,by=1))
# We can take a similar approach to look at trends over time.
highest_year = as.data.frame(data$PY)
highest_year$maintopic = topics(LDA200, k = 1)
crosstabtable_year = table(highest_year)
bar3 <-barplot(crosstabtable_year,legend.text = c("2011", "2012","2013","2014","2015"),col = c("gray0","gray20","gray60","gray80","gray100"), axisnames=FALSE)
axis(3,at=bar3,labels=seq(1,200,by=1))
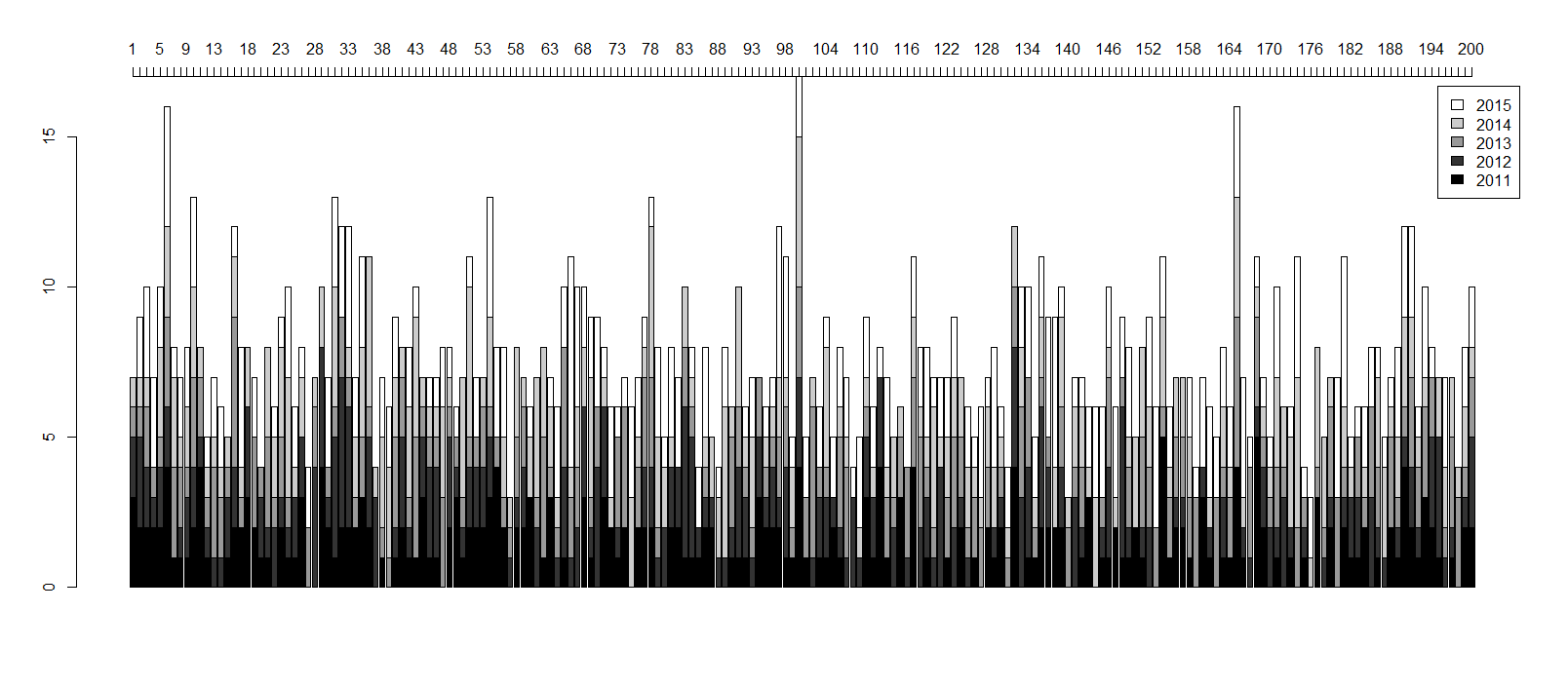
bar4 <-barplot(crosstabtable[1,], axisnames=FALSE)
axis(3,at=bar4,labels=seq(1,200,by=1))